Fine-tuning Language Models on Apple Silicon with MLX
Our take
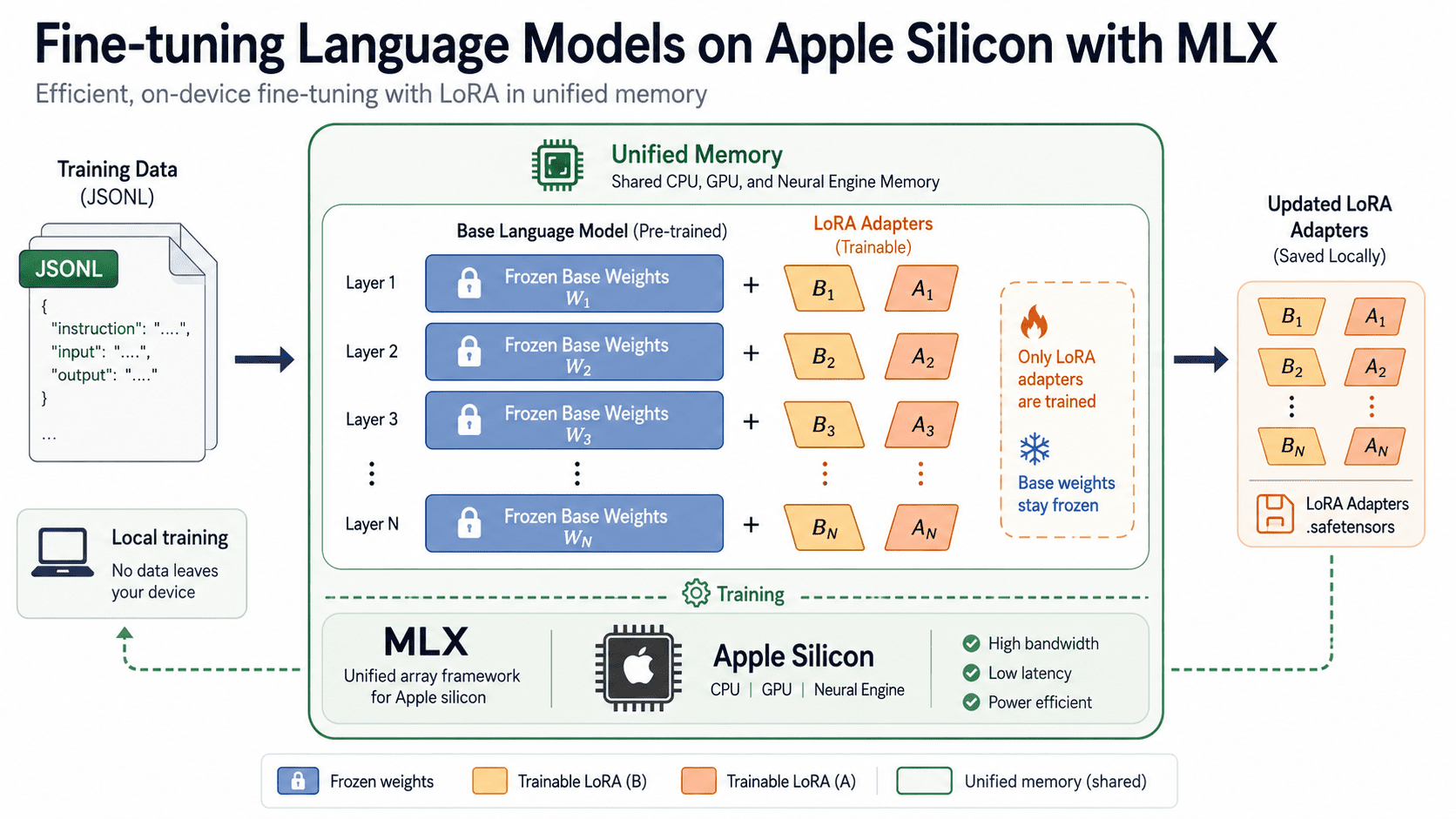
The recent announcement of MLX, Apple’s framework for machine learning on Apple Silicon, and its direct facilitation of locally hosted language model fine-tuning, represents a significant shift in the accessibility of advanced AI development. The ability to fine-tune open language models directly on a Mac, bypassing the need for expensive cloud GPU resources or recurring costs, democratizes access to a technology that was previously largely confined to well-funded research labs and corporations. This aligns with a broader trend toward edge computing and localized AI processing, and builds on previous efforts to optimize machine learning workflows; consider, for example, the work being done on simulators for high fidelity vision RL training natively on GPU [MuJoCo derived Simulator for High Fidelity Vision RL training natively on GPU]. The implications for individual developers, researchers, and smaller teams are profound, opening up opportunities for experimentation and innovation previously out of reach. It’s a welcome development, particularly given the ongoing exploration of specialized programming languages designed to streamline LLM development [Would having a dedicated programming language specifically for LLMs be a viable solution?].
The core advantage of MLX lies not just in its cost-effectiveness, but also in its potential for enhanced privacy and control. Running models locally eliminates the need to transmit sensitive data to external servers, a crucial consideration for applications involving personal information or proprietary datasets. This resonates with a growing demand for data sovereignty and responsible AI practices. Furthermore, local fine-tuning allows for rapid iteration and experimentation, as developers can quickly evaluate the impact of different training datasets and hyperparameters without the delays associated with cloud-based infrastructure. The barrier to entry for testing specific use cases, tailoring models to niche domains, or simply exploring the nuances of language model behavior is dramatically lowered. This is a practical step toward empowering a wider range of individuals and organizations to shape the future of AI, rather than relying solely on large, centralized providers. The agility afforded by local processing is increasingly vital in a rapidly evolving field, where staying ahead of the curve requires constant adaptation and experimentation— a principle also seen in the efforts to create superhuman agents through self-play RL [I made a superhuman Generals.io agent with self-play RL].
However, it’s important to acknowledge the current limitations of MLX. While Apple Silicon offers impressive performance, it’s unlikely to match the sheer computational power of high-end cloud GPUs, particularly for extremely large language models. Fine-tuning will likely be more practical for smaller models or targeted adjustments to existing models, rather than training entirely new behemoths from scratch. The initial release of MLX and its associated tools is also relatively nascent, meaning the developer ecosystem and available resources are still maturing. Over time, we can expect to see increased support, optimization, and integration with other frameworks and libraries, further enhancing its usability and expanding its capabilities. The early adoption and feedback from the community will be critical in shaping the future direction of MLX and its impact on the broader AI landscape.
Looking ahead, the convergence of accessible hardware, optimized frameworks like MLX, and the continued proliferation of open language models points toward a future where AI development is more decentralized, personalized, and democratized. While cloud-based AI will undoubtedly remain a dominant force for large-scale training and deployment, the ability to leverage local resources for fine-tuning, experimentation, and specialized applications represents a powerful and transformative shift. The question now becomes: how will this newfound accessibility reshape the landscape of AI innovation and empower a new generation of creators and problem-solvers?
Read on the original site
Open the publisher's page for the full experience