GraphRAG vs Vector RAG: Which Retrieval Method is Best?
Our take
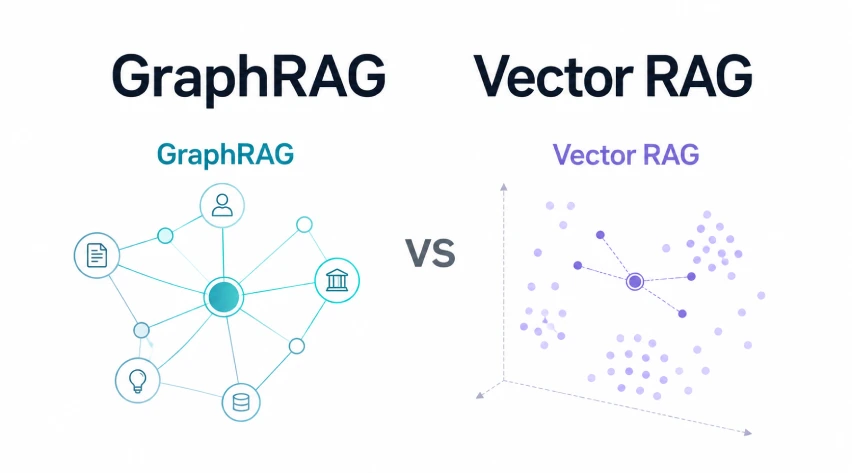
The debate between Vector RAG and GraphRAG highlights a crucial inflection point in the evolution of Retrieval-Augmented Generation (RAG) systems. As organizations increasingly rely on LLMs to access and synthesize information, the underlying retrieval mechanism becomes paramount. The Analytics Vidhya piece effectively lays out the core differences: Vector RAG’s simplicity and speed of implementation versus GraphRAG’s added structural layer. Vector RAG, as described, is a pragmatic starting point, particularly advantageous when the answers you seek are neatly contained within a few key passages. However, many real-world knowledge bases are far more complex, involving intricate relationships and dependencies that a purely semantic search struggles to capture. This complexity is further explored in our own work evaluating [Evaluating long-term memory limits in stateless LLM chatbots — feedback needed], which underscores the challenges of maintaining context and accuracy across extended interactions, a problem often exacerbated by simplistic retrieval strategies. Understanding these nuances is essential for building truly robust and reliable LLM applications.
The shift towards GraphRAG signals a move toward representing knowledge in a more human-like manner. By explicitly extracting entities, relationships, and communities, GraphRAG allows LLMs to reason about the *connections* between pieces of information, not just their semantic similarity. This approach is particularly valuable when dealing with complex documents, such as legal contracts, scientific literature, or internal knowledge repositories. Consider the example of building an ML model to "watch" MMA fights and label events, as showcased in [Showcase: Building ML models that "watch" MMA fights and label events and positional changes making these moments all searchable on a timeline]. The ability to understand the relationships between fighters, techniques, and events is critical for accurate labeling and analysis – a task that would likely benefit from a graph-based approach. Furthermore, the development of frameworks that enable LLM training on older GPUs, such as the one detailed in [Built an LLM training framework that actually runs on older GPUs without crashing], demonstrates a growing accessibility of these more computationally intensive techniques.
The choice between Vector RAG and GraphRAG isn’t necessarily an either/or proposition. In many cases, a hybrid approach—combining the speed of vector search with the contextual understanding of graph-based retrieval—will offer the best results. The key takeaway is that the optimal retrieval method is deeply dependent on the specific use case and the nature of the data being queried. As LLMs continue to evolve, we can expect to see even more sophisticated retrieval techniques emerge, blurring the lines between semantic search, knowledge graphs, and other forms of structured data representation. The current focus on RAG methodologies is a testament to the fact that the LLM itself is only half the equation; the quality and efficiency of the retrieval process are equally critical to achieving meaningful outcomes.
Ultimately, the ongoing development of both Vector and GraphRAG represents a crucial step towards unlocking the full potential of LLMs. The increasing sophistication of these retrieval methods allows us to move beyond simple question-answering and towards more complex tasks such as knowledge discovery, reasoning, and automated decision-making. A critical question moving forward is how we can effectively automate the construction and maintenance of these knowledge graphs—a task that currently relies heavily on manual effort and expertise. Can we develop AI-powered tools that can automatically extract entities, relationships, and communities from unstructured data, thereby democratizing access to the transformative power of GraphRAG?
GraphRAG and Vector RAG address different retrieval needs. Vector RAG splits documents into chunks, embeds them, retrieves semantically similar passages, and sends them to an LLM. It is simple, fast to build, and works best when answers sit within one or two relevant chunks. GraphRAG adds structure by extracting entities, relationships, and communities, making it […]
The post GraphRAG vs Vector RAG: Which Retrieval Method is Best? appeared first on Analytics Vidhya.
Read on the original site
Open the publisher's page for the full experience