Sub-JEPA: a simple fix to LeCun group's LeWorldModel that consistently improves performance [P]
Our take
The recent work by the LeCun group at NYU on the LeWorldModel (LeWM) highlights a significant advancement in the realm of world models, which are crucial for learning compact latent representations for planning without relying on pixel reconstruction. While LeWM has demonstrated stable end-to-end training through its isotropic Gaussian prior, it falls short in scenarios where real-world dynamics are better represented as low-dimensional manifolds. This limitation is particularly pronounced in tasks with low intrinsic dimensions, such as the Two-Room task. The introduction of Sub-JEPA as a solution to this issue offers a promising alternative that not only addresses the rigidity of the global high-dimensional Gaussian prior but does so while maintaining the benefits of regularization.
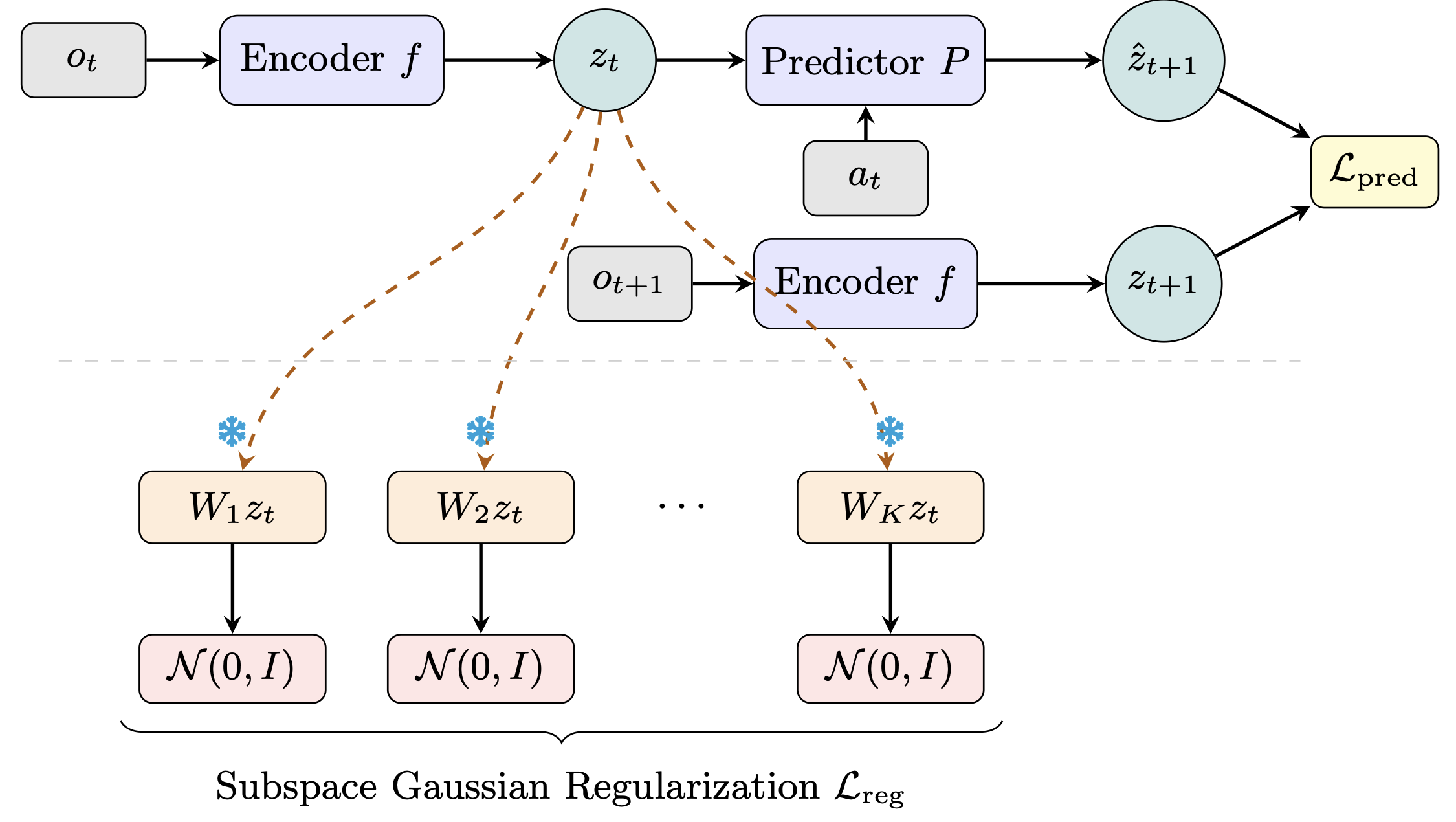
The innovation behind Sub-JEPA lies in applying Gaussian regularization within multiple frozen random orthogonal subspaces, thereby allowing for a more flexible approach to modeling the task geometry. This modification alleviates the constraints imposed by the global prior while still preventing the collapse of latent representations. Such improvements are not merely technical; they have tangible implications for performance. The reported results show consistent outperformance of Sub-JEPA over LeWM across various benchmarks, achieving a notable increase of up to 10.7 percentage points on the Two-Room task. These enhancements in the model's performance underscore the importance of aligning model architecture with the intricacies of real-world data dynamics.
This development speaks volumes about the ongoing evolution of AI and machine learning techniques, particularly in how we approach data representation and modeling. As the field continues to advance, the need for more adaptable and user-friendly tools becomes increasingly evident. For example, an understanding of advanced SQL functions can significantly empower data scientists in their work, as highlighted in our article on 40 Advanced SQL Window Functions Every Data Scientist Must Know(with examples). Just as the Sub-JEPA approach refines the modeling of latent spaces, so too do effective data management practices enhance productivity and insight extraction.
Moreover, the implications of these advancements extend beyond technical performance; they indicate a shift towards more human-centered AI solutions. As users increasingly seek tools that simplify complex workflows, understanding these developments can be crucial. For instance, the challenges faced by users of legacy spreadsheet tools are echoed in our piece on How to make excel subtract a cell based on the text of another cell?. By addressing such user pain points through innovative solutions like Sub-JEPA, we not only improve model performance but also enhance the overall user experience in data management.
As we look to the future, the success of Sub-JEPA raises important questions about the next steps in AI model development. Will we see more researchers adopt similar approaches that prioritize flexibility and user-centric design? As the landscape of AI continues to evolve, staying attuned to these trends will be essential for ensuring that we harness the full potential of these technologies. The pursuit of adaptable, efficient, and accessible AI solutions is not just a technical endeavor; it represents a broader commitment to empowering users and transforming how we interact with data.
World models learn compact latent representations for planning without pixel reconstruction. LeWorldModel (LeWM), from LeCun's group at NYU, achieves stable end-to-end JEPA training by enforcing an isotropic Gaussian prior over the full latent space.
The flaw: real environment dynamics live on low-dimensional manifolds, so a global high-dimensional Gaussian is an overly rigid prior — mismatched to the task geometry. LeWM itself struggles most on low-intrinsic-dimension tasks like Two-Room.
Our fix (Sub-JEPA): apply the Gaussian regularization inside multiple frozen random orthogonal subspaces instead. This relaxes the global constraint while keeping the anti-collapse benefit. No new hyperparameters, same two-term objective.
Sub-JEPA consistently outperforms LeWM across all four benchmarks, with up to +10.7 pp on Two-Room. We also observe straighter latent trajectories and better physical state decodability as emergent benefits.
{kind=link}

{kind=link}
🌐 Project: https://kaizhao.net/sub-jepa
💻 Code: https://github.com/intcomp/sub-jepa
📄 Paper: https://arxiv.org/pdf/2605.09241
[link] [comments]
Read on the original site
Open the publisher's page for the full experience